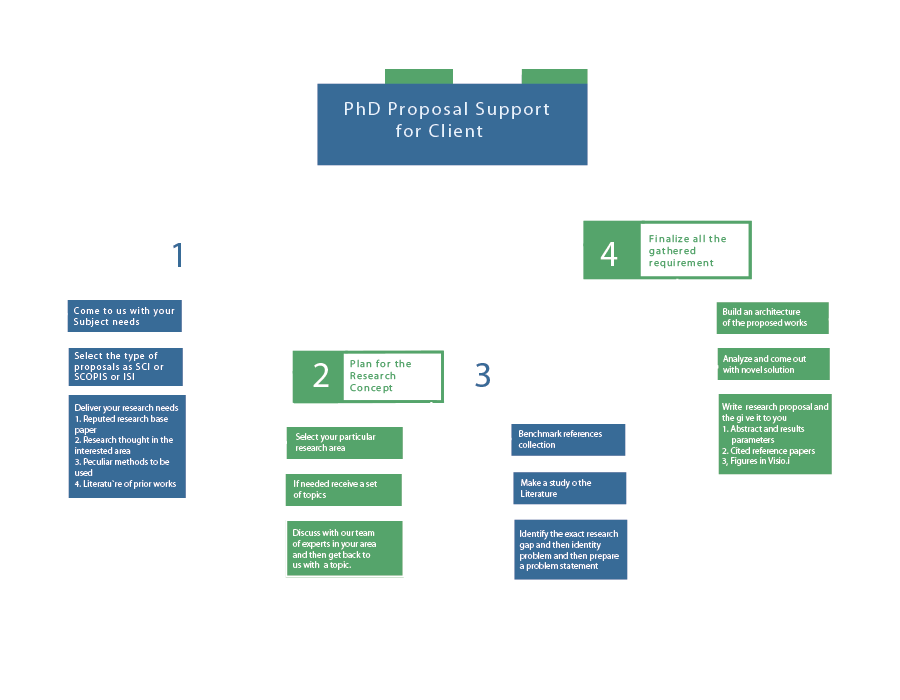
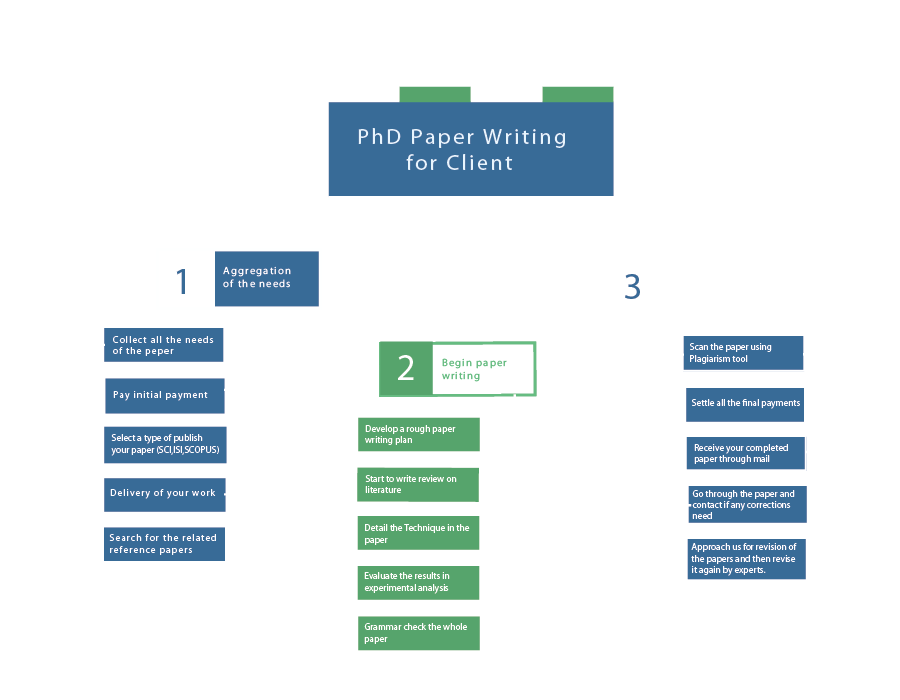
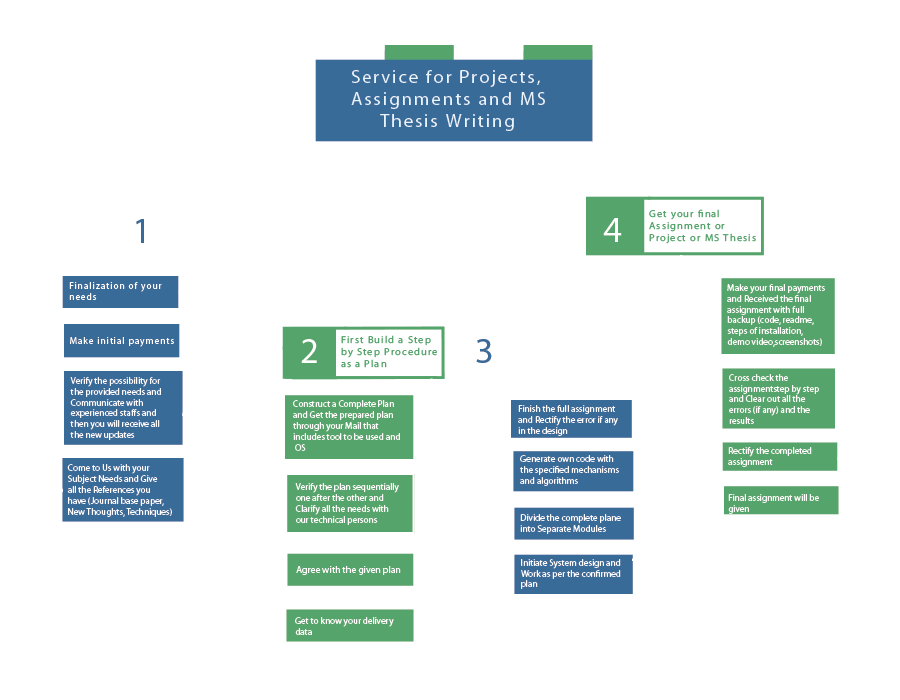
Are you struggling with your NLP thesis? Don’t worry, we understand that it can be challenging for scholars. But fear not, because our team of experts is here to help you achieve excellent results. With our access to various data collection methods, data analysis techniques, and cutting-edge tools, we have everything you need to taste success. Stay connected with us and let us guide you towards your academic triumph. Data analysis is an important process, which implements various major techniques on data for several purposes. To carry out the data analysis process for your NLP-based thesis, we assist you by offering an extensive guideline, along with potential instances:
- Define Goals and Research Queries
- Your research queries and thesis goals have to be summarized in an explicit way. Note that this process will direct your data analysis properly.
Sample Goals:
- For product reviews, a sentiment analysis framework must be developed.
- Specifically for technical support reports, create a question-answering model.
- Gather or Prepare Data
- Develop a dataset by your own or detect suitable datasets.
- It is approachable to obtain datasets with APIs or examine the datasets that are openly accessible.
Sample Public Datasets:
- Topic Modeling: 20 Newsgroups.
- Named Entity Recognition (NER): CoNLL-2003, OntoNotes.
- Sentiment Analysis: IMDb Reviews, Yelp Reviews.
- Translation: WMT, IWSLT.
- Question Answering (QA): SQuAD, Natural Questions, MS MARCO.
Conventional Data Gathering:
- APIs: Consider various APIs like Reddit API, Twitter API, etc.
- Web scraping: For web scraping, employ Scrapy or Beautiful Soup.
- Data Preprocessing and Cleaning
- Tokenization
- Lemmatization or stemming
- Lowercasing
- Elimination of HTML tags, special characters, and stop words.
Instance Code (Python):
import re
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from nltk.stem import WordNetLemmatizer
# Download NLTK resources
nltk.download(‘punkt’)
nltk.download(‘stopwords’)
nltk.download(‘wordnet’)
# Sample text
text = “This is a sample review for preprocessing in NLP!”
# Tokenization
tokens = word_tokenize(text)
# Lowercasing and removing special characters
tokens = [re.sub(r’\W+’, ”, word.lower()) for word in tokens if word.isalnum()]
# Stop words removal
stop_words = set(stopwords.words(‘english’))
tokens = [word for word in tokens if word not in stop_words]
# Lemmatization
lemmatizer = WordNetLemmatizer()
tokens = [lemmatizer.lemmatize(word) for word in tokens]
print(tokens)
- Exploratory Data Analysis (EDA)
- Descriptive Statistics
- Fundamental Analysis:
- Vocabulary dimension
- For categorization missions, consider class distribution.
- Average document length
- Count of documents
Instance Code (Python)
import pandas as pd
# Load dataset
data = pd.read_csv(‘reviews.csv’)
# Number of documents
num_docs = len(data)
# Average document length
avg_doc_length = data[‘review’].apply(lambda x: len(x.split())).mean()
# Vocabulary size
all_words = ‘ ‘.join(data[‘review’]).split()
vocab_size = len(set(all_words))
# Class distribution
class_dist = data[‘sentiment’].value_counts()
print(f’Number of documents: {num_docs}’)
print(f’Average document length: {avg_doc_length:.2f}’)
print(f’Vocabulary size: {vocab_size}’)
print(f’Class distribution:\n{class_dist}’)
- Visualizations
- Word Cloud: Visualization of common terms.
Instance Code (Word Cloud):
from wordcloud import WordCloud
import matplotlib.pyplot as plt
text = ‘ ‘.join(data[‘review’])
wordcloud = WordCloud(width=800, height=400, max_words=100).generate(text)
plt.figure(figsize=(10, 5))
plt.imshow(wordcloud, interpolation=’bilinear’)
plt.axis(‘off’)
plt.show()
- Class Distribution: Consider the visualization of class distribution.
Instance Code (Class Distribution):
import seaborn as sns
sns.countplot(x=’sentiment’, data=data)
plt.xlabel(‘Sentiment’)
plt.ylabel(‘Count’)
plt.title(‘Sentiment Class Distribution’)
plt.show()
- Text Length Distribution: The distribution of text lengths has to be examined.
Instance Code (Text Length Distribution):
data[‘text_length’] = data[‘review’].apply(lambda x: len(x.split()))
sns.histplot(data[‘text_length’], bins=30, kde=True)
plt.xlabel(‘Number of Words’)
plt.ylabel(‘Count’)
plt.title(‘Text Length Distribution’)
plt.show()
- Feature Engineering
- Bad-of-words (BoW): It is beneficial to utilize term frequency-inverse document frequency (TF-IDF) or basic word counts.
Instance Code (TF-IDF):
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf_vectorizer = TfidfVectorizer(max_features=5000)
tfidf_features = tfidf_vectorizer.fit_transform(data[‘review’]).toarray()
- Word Embeddings: Use various pre-trained embeddings such as FastText, GloVe, or Word2Vec.
Instance Code (GloVe Embeddings):
import numpy as np
# Load pre-trained GloVe embeddings
embedding_dict = {}
with open(‘glove.6B.50d.txt’, ‘r’, encoding=’utf-8′) as file:
for line in file:
values = line.split()
word = values[0]
vector = np.array(values[1:], dtype=’float32′)
embedding_dict[word] = vector
# Embedding representation for a sample document
def get_glove_embeddings(text, embedding_dict, dim=50):
words = text.split()
embeddings = np.zeros((dim,))
valid_words = [embedding_dict[word] for word in words if word in embedding_dict]
if valid_words:
embeddings = np.mean(valid_words, axis=0)
return embeddings
# Apply to all documents
data[‘glove_embedding’] = data[‘review’].apply(lambda x: get_glove_embeddings(x, embedding_dict))
- Sequence Modeling Characteristics: For transformers or recurrent neural networks (RNNs), create input series.
Instance Code (Keras Tokenizer):
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
# Initialize tokenizer and fit on text data
tokenizer = Tokenizer(num_words=10000)
tokenizer.fit_on_texts(data[‘review’])
# Convert texts to sequences
sequences = tokenizer.texts_to_sequences(data[‘review’])
# Pad sequences to the same length
padded_sequences = pad_sequences(sequences, maxlen=100)
- Baseline Model Training and Assessment
- As a baseline model, a basic deep learning or machine learning model has to be trained.
Instance Code (Logistic Regression Baseline):
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, accuracy_score
# Split data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(tfidf_features, data[‘sentiment’], test_size=0.2, random_state=42)
# Train a logistic regression model
model = LogisticRegression(max_iter=1000)
model.fit(X_train, y_train)
# Predict on test data
y_pred = model.predict(X_test)
# Evaluate model
print(f’Accuracy: {accuracy_score(y_test, y_pred):.2f}’)
print(classification_report(y_test, y_pred))
- Analysis of Outcomes and Discussion
- The baseline outcomes must be examined and explained.
- It is approachable to emphasize any problems, contradictions, and possible enhancements for further research.
- Additional Procedures
- Investigate the latest NLP-based models such as GPT or BERT, adjust hyperparameters, or improve your model infrastructure.
- Repeat the process using cross-validation. Then, enhance feature engineering or data preprocessing efficiently.
What is a good topic for a master’s thesis in software engineering related to natural language processing and machine learning?
Software engineering based on machine learning and natural language processing is an interesting and significant research area. Relevant to this area, there are several research topics and ideas. The following are a few compelling topics, which are appropriate for a master’s thesis:
- Automated Code Generation from Natural Language Descriptions
- Issue: Creation of applicable code by translating human-accessible descriptions.
- Plan:
- Aim to create a framework, which employs various pre-trained language models such as CodeT5 or GPT-3 for converting natural language explanations into workable code.
- In order to assure that the created code follows descriptions, include a validation technique.
- Research Queries:
- How well can extensive language models produce precise code from natural language?
- What is the contribution of domain adaptation in the process of enhancing code generation?
- Major Challenges:
- Managing domain-based necessities.
- Development of an efficient dataset based on NL-code pairs.
- Natural Language Requirements Engineering
- Issue: From documents, retrieve, categorize, and verify the specifications of software.
- Plan:
- Employ NLP approaches such as relationship extraction and named entity recognition (NER), specifically for applying a requirements engineering system.
- To classify necessities into practical and impractical types, create a classifier.
- By utilizing ontologies or dependency parsing, offer a verification technique.
- Research Queries:
- How precisely can NLP frameworks categorize and retrieve specifications?
- How can specifications be depicted for simpler verification?
- Major Challenges:
- Creation of specifications dataset in an extensive manner.
- Another challenge is working with partial and unclear specifications.
- Bug Report Classification and Prioritization Using NLP and ML
- Issue: To minimize response time, categorize and prefer bug reports in an automatic manner.
- Plan:
- Focus on creating a model, which categorizes bug reports in terms of effects or risks through the use of NLP approaches.
- For suggesting the highly important bugs, a prioritization method has to be applied by utilizing categorization results.
- Research Queries:
- How well can ML-based frameworks categorize bug reports on the basis of risk?
- Which prioritization policy outputs the rapid response times?
- Major Challenges:
- In accordance with industry principles, create a prioritization metric.
- Development or detection of labeled dataset related to bug reports.
- Source Code Summarization and Documentation Generation
- Issue: For source code functions, create documentation and outlines in an automatic way.
- Plan:
- Employ pre-trained language models such as GraphCodeBERT or CodeBERT to apply a summarization model.
- As a means to create human-accessible, elaborate documentation or outlines, adjust the model.
- For assessing the standard of created outlines, an assessment architecture must be developed.
- Research Queries:
- For source code, how accurately can pre-trained models create outlines or documentation?
- Which assessment metrics evaluate the standard of outline in an efficient way?
- Major Challenges:
- Relevant to coding outlines, create a different dataset.
- For automatic code summarization, develop a standard metric.
- Refactoring Suggestions Using Machine Learning and NLP
- Issue: In software projects, detect and recommend possible refactorings.
- Plan:
- To identify code natures and recommend suitable refactorings, a model has to be trained on code change histories.
- For obtaining and applying these recommendations in a perfect manner, create an interface for programmers.
- Research Queries:
- How well are code change histories in the process of detecting code natures?
- What integration of characteristics forecast valuable refactorings in an effective way?
- Major Challenges:
- Collection of high-standard dataset relevant to the instances of refactoring.
- To depict recommendations, consider the development of an accessible interface.
- Cross-Lingual Source Code Analysis
- Issue: Among various programming languages, examine source code.
- Plan:
- Utilize multilingual transformers like XLM-R or mBERT for creating a cross-lingual code analysis tool.
- In order to adjust models with programming languages and offer integrated analysis outcomes, implement transfer learning techniques.
- Research Queries:
- To what extent the multilingual models generalize with various programming languages?
- For efficient cross-lingual analysis, what preprocessing procedures are important?
- Major Challenges:
- With various programming languages, develop a coherent depiction.
- In terms of different programming models, assess the analysis tool.
- Automated Test Case Generation from User Stories
- Issue: From active user narratives, create samples in an automatic manner.
- Plan:
- Intend to construct a model, which creates samples by retrieving major details from user narratives.
- Find activities, participants, and results through the utilization of BERT-based entity extraction or dependency parsing.
- Research Queries:
- How do various depiction techniques affect the standard of samples?
- How efficiently can the NLP model create samples from user narratives?
- Major Challenges:
- Development of user narratives-based dataset, along with relevant samples.
- Major challenge is to match created samples with the requirements of the software.
- Conversational AI for Software Development Assistance
- Issue: By means of chatbots, offer actual-time and wise support, especially to software developers.
- Plan:
- To assist developers based on project reports, syntax problems, or coding regulations, create an interactive assistant.
- For offering perfect recommendations and enhancements, combine the bot into an IDE.
- Research Queries:
- How can the combination of IDE enhance the efficiency of developers?
- What interactive policies assist software developers in an optimal way?
- Major Challenges:
- To interpret complicated programming questions, model a natural language interface.
- Enabling various programming languages and combination with several IDEs are the significant challenges.
- Machine Learning-Based Vulnerability Detection in Source Code
- Issue: In software projects, consider the detection of safety risks.
- Plan:
- From static code analysis, identify risks by applying a deep learning framework.
- Use the familiar risk datasets to train the framework. To various software projects, implement transfer learning.
- Research Queries:
- How accurate are machine learning frameworks in the process of detecting safety risks?
- What is the implication of transfer learning on cross-project risk identification?
- Major Challenges:
- Development of risk-based labeled dataset.
- Among different safety principles and programming languages, assess identification frameworks.
Selecting a Topic
- Connect with Interests and Skills:
- It is important to assure that the chosen topic fits with your technical capabilities as well as intriguing.
- Assess Practicality:
- Examine various major aspects such as project intricateness, necessary tools, and data accessibility.
- Discuss with Mentors and Industry Experts:
- Converse with your mentors or industrial specialists for enhancing the selected topic.
- Narrow Down Research Queries:
- A collection of research queries has to be developed in a feasible and explicit manner.