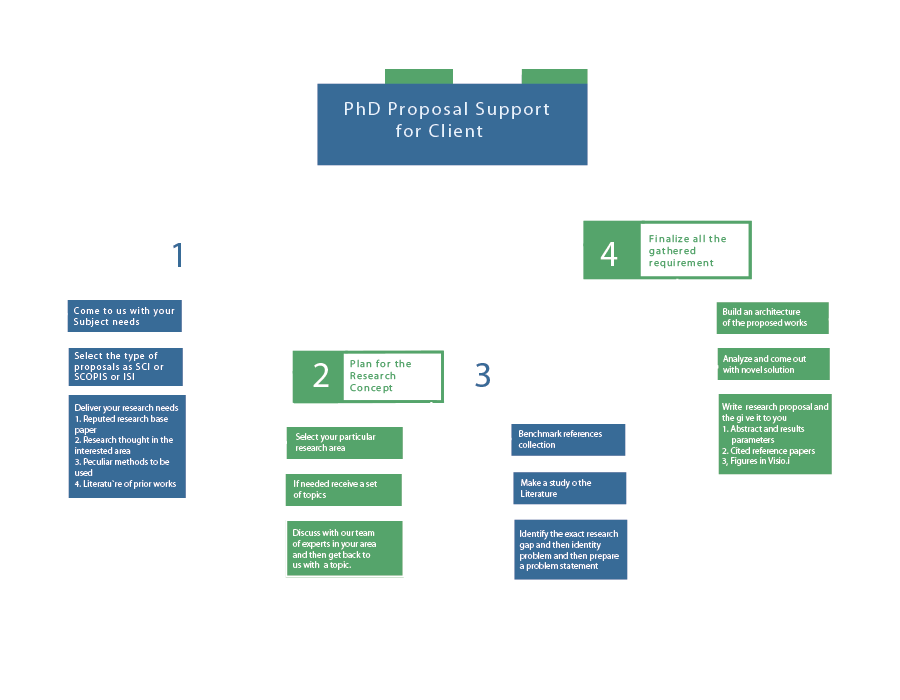
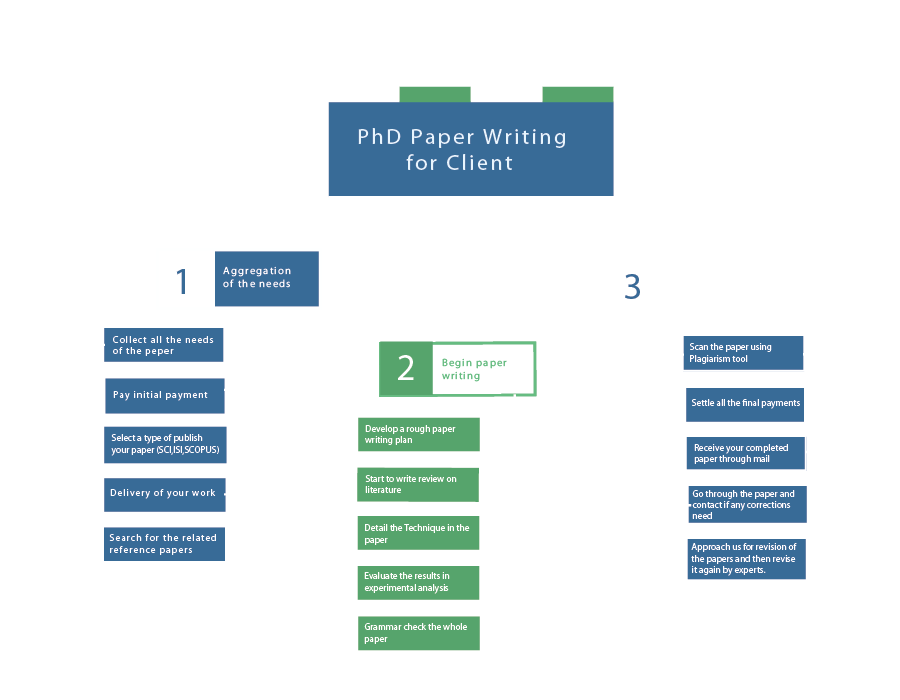
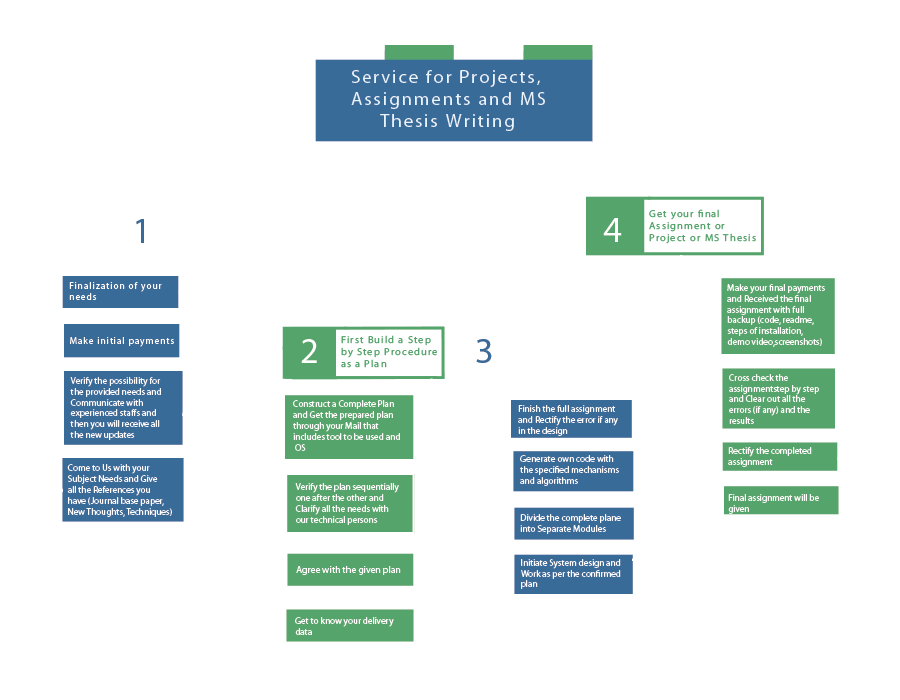
In the domain of Natural Language Processing (NLP), there are numerous projects that are emerging in recent years. The following are the projects that denote current developments in transformer systems, multimodal AI, cross-lingual learning, and more have a look at it and contact us for more experts touch in the field of NLP:
- Zero-Shot Cross-Lingual Text Classification
Explanation:
- To categorize text among numerous languages, aim to develop a multilingual framework with zero-shot learning.
- It is appreciable to utilize frameworks such as mBERT or XLM-R and adjust them for document categorization, sentiment analysis, or NER.
Characteristics:
- For enhanced effectiveness, it offers domain adaptation approaches.
- Zero-shot learning is examined as suitable for cross-lingual missions.
Research Queries:
- How do various training policies influence zero-shot effectiveness?
Tools:
- XLM-R, IndicNLP, Transformers (Hugging Face), mBERT.
- Conversational AI for Mental Health Support
Explanation:
- To offer psychological welfare assistance, construct an understanding conversational agent.
- Generally, sentiment analysis and emotion identification have to be combined to provide customized reactions.
Characteristics:
- It contains multiturn conversation management together with memory and setting awareness.
- To customize dialogues, perform sentiment and emotion identification.
Research Queries:
- How to stabilize understanding and accurate reactions in psychological welfare chatbots?
Tools:
- DialoGPT, spaCy, GPT-4 API, NLTK, Rasa.
- Automated Legal Document Analysis
Explanation:
- Focus on computerizing the extraction of major information from judicial documents, like court rulings or contracts.
- It is approachable to utilize NER, relationship extraction, and text summarization approaches.
Characteristics:
- This study includes Named entity recognition (NER) along with domain-specific entity kinds.
- Typically, it provides contract clause categorization and summarization.
Research Queries:
- How to develop a combined model for obtaining different kinds of information from judicial documents?
Tools:
- Transformers, Gensim, spaCy, docx2txt, AllenNLP.
- Multimodal Sentiment Analysis for Social Media Posts
Explanation:
- From social media posts, examine sentiments that encompass images, videos, and text.
- To generate text and image characteristics, employ transformers such as VisualBERT.
Characteristics:
- For integrating image, text, and audio characteristics, joint attention technology is appropriate.
- Specifically, for improved sentiment analysis provides multimodal fusion.
Research Queries:
- How do various multimodal fusion approaches influence sentiment analysis effectiveness?
Tools:
- LXMERT, OpenCV, MMF (Facebook AI), PyTorch, VisualBERT.
- Fake News Detection Using Graph Neural Networks
Explanation:
- To examine the connections among news articles and resources, identify fake news through the utilization of graph neural networks (GNNs).
- Generally, engagement data, propagation paths, and source reliability has to be employed as characteristics.
Characteristics:
- This project offers graph construction from social network data.
- It has the ability to combine source reliability and user involvement.
Research Queries:
- How to depict social network architectures efficiently in graph neural networks?
Tools:
- NetworkX, Hugging Face Transformers, DGL (Deep Graph Library).
- Explainable Question Answering System
Explanation:
- A question-answering (QA) model has to be constructed in such a manner that offers descriptions for its answers.
- For answer descriptions, aim to combine attention mechanisms and counterfactual analysis.
Characteristics:
- To describe QA framework choices, attention visualization is efficient.
- Counterfactual explanations are offered in order to detect relevant settings.
Research Queries:
- How to produce eloquent descriptions for complicated question answering missions?
Tools:
- AllenNLP, LIME, SHAP, Hugging Face Transformers, ELI5 (Explain Like I’m Five).
- Program Synthesis from Natural Language Descriptions
Explanation:
- To transform natural language programming requirements into executable code, develop an appropriate framework.
- On code generation missions, instruct CodeT5 or GPT-3 systems.
Characteristics:
- It contains the capability to transform English guidelines into Python code snippets.
- Provides communicative interface to instruct code synthesis.
Research Queries:
- How efficient are extensive language systems in interpreting software engineering requirements?
Tools:
- CodeT5, spaCy, OpenAI GPT-3 API, PyTorch.
- Ethical Bias Detection and Mitigation in NLP Models
Explanation:
- By utilizing adversarial training and data augmentation approaches, detect and reduce unfairness in NLP frameworks.
- In NER, word embeddings, and sentiment analysis frameworks, focus on examining unfairness.
Characteristics:
- For word embeddings, it provides hard and soft debiasing techniques.
- In downstream missions such as NER and categorization, bias identification is suitable.
Research Queries:
- What influence does data augmentation have on decreasing unfairness in NLP systems?
Tools:
- Allennlp Interpret, Transformers, Word Embedding Association Test (WEAT), Fairlearn.
- Multi-Task Learning for Financial Document Analysis
Explanation:
- To obtain and examine information from financial documents, it is appreciable to implement multi-task learning.
- Focus on integrating missions such as sentiment analysis, financial summarization, and NER.
Characteristics:
- For numerous financial NLP missions, the joint learning model is determined as appropriate.
- To enhance effectiveness, perform transfer learning among relevant missions.
Research Queries:
- How efficient is task-specific pre-training for multi-task financial NLP?
Tools:
- PyTorch, FinBERT, Hugging Face Transformers, FinancialPhraseBank.
- Human-AI Collaboration for Content Moderation
Explanation:
- A collaborative content moderation tool has to be constructed that integrates human experience with AI frameworks.
- For labelling offensive, false, or spam content, focus on offering AI recommendations.
Characteristics:
- To improve AI recommendations on the basis of human review, an active learning model is efficient.
- For complicated content kinds, it offers multi-label categorization.
Research Queries:
- How to formulate a human-AI interface that reduces labelling endeavour when enhancing precision?
Tools:
- Transformers, Streamlit, Label Studio, Active Learning Library.
What is a good project combining computer vision and NLP?
There are several projects which involve integrating computer vision and NLP, but some are determined as efficient. We offer an extensive plan for a project that combines both of these domains:
Project: Visual Storytelling from Image Sequences
Goal: By employing the advantages of computer vision as well as natural language processing, construct a model that produces consistent narratives or stories from a series of images.
Application Areas:
- For event photography, used in constructing automated lectures or storytelling.
- It is utilized in developing story narratives from photo albums.
- In generating stories and captions for academic materials.
Major Components and Methodology:
- Dataset Preparation
- Dataset Instances:
- VIST (Visual Storytelling Dataset): This dataset involves image series along with ground-truth stories.
- MS COCO Captions Dataset: It offers captions for individual images.
- Flickr8k/Flickr30k: This dataset encompasses the image-caption pairs.
- Preprocessing Steps:
- By utilizing OpenCV, assure coherent image sizes.
- Aim to tokenize and cleanse text stories through employing NLP preprocessing tools.
- Image Feature Extraction
- By means of employing a pre-trained convolutional neural network (CNN), focus on obtaining visual characteristics from every image in the series.
Instance Code (Image Feature Extraction using ResNet):
import torch
import torchvision.models as models
import torchvision.transforms as transforms
from PIL import Image
# Load pre-trained ResNet model
resnet = models.resnet50(pretrained=True)
resnet.eval()
modules = list(resnet.children())[:-1]
resnet = torch.nn.Sequential(*modules)
# Image preprocessing
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
def extract_image_features(image_path):
image = Image.open(image_path).convert(‘RGB’)
image = transform(image).unsqueeze(0)
with torch.no_grad():
features = resnet(image)
return features.squeeze().numpy()
# Example usage
features = extract_image_features(‘example_image.jpg’)
- Story Generation Model
- To produce consistent stories on the basis of image series, utilize a sequence-to-sequence framework.
- Encoder: It offers the visual characteristics that are obtained through CNN.
- Decoder: To produce text stories, it provides a transformer or LSTM network.
Instance Code (Story Generation Model):
import torch
import torch.nn as nn
class VisualStoryTellingModel(nn.Module):
def __init__(self, image_feature_dim, hidden_dim, vocab_size): super(VisualStoryTellingModel, self).__init__()
self.encoder = nn.Linear(image_feature_dim, hidden_dim)
self.lstm = nn.LSTM(hidden_dim, hidden_dim, batch_first=True)
self.fc = nn.Linear(hidden_dim, vocab_size)
def forward(self, image_features, captions):
features = self.encoder(image_features)
features = features.unsqueeze(1).repeat(1, captions.size(1), 1)
lstm_out, _ = self.lstm(features)
outputs = self.fc(lstm_out)
return outputs
- Text Generation Refinement
- Typically, beam search or nucleus sampling has to be utilized to enhance the standard of the generated text.
- For adjusting and efficient tone, employ a pre-trained language system such as GPT-2.
Instance Code (Beam Search):
def beam_search_decoder(predictions, beam_width):
sequences = [[list(), 0.0]]
for row in predictions:
all_candidates = list()
for seq, score in sequences:
for idx, prob in enumerate(row):
candidate = [seq + [idx], score – np.log(prob)]
all_candidates.append(candidate)
ordered = sorted(all_candidates, key=lambda x: x[1])
sequences = ordered[:beam_width]
return sequences
- Evaluation Metrics
- ROUGE Score: This parameter calculates recall-oriented similarity among the generated and ground-truth stories.
- BLEU Score: Generally, the BLEU score is determined as a precision-oriented metric. It is beneficial for assessing machine-generated text.
- CIDEr Score: The CIDEr score seizes consensus-related similarity to human-generated stories.
Instance Code (Evaluation with BLEU Score):
from nltk.translate.bleu_score import sentence_bleu
reference = [[‘a’, ‘man’, ‘is’, ‘playing’, ‘guitar’]]
candidate = [‘a’, ‘man’, ‘is’, ‘playing’, ‘the’, ‘guitar’]
score = sentence_bleu(reference, candidate)
print(f’BLEU score: {score:.4f}’)
from nltk.translate.bleu_score import sentence_bleu
reference = [[‘a’, ‘man’, ‘is’, ‘playing’, ‘guitar’]]
candidate = [‘a’, ‘man’, ‘is’, ‘playing’, ‘the’, ‘guitar’]
score = sentence_bleu(reference, candidate)
print(f’BLEU score: {score:.4f}’)
- Extension Ideas:
- Emotion-Based Storytelling:
- Through the utilization of image categorization or facial detection, identify emotions in images.
- To indicate the recognized emotions, aim to generate stories.
- Personalization:
- It is approachable to combine user priorities or styles into the storytelling framework.
- Interactive Story Generation:
- To instruct the generated narrative, it facilitates users to offer biased captions or main story components.